

数据库性能优化的应用场景相当广泛,但SQL语句与业务联系紧密,代码层面的优化可能需要花费相当多的时间与精力。除了代码层面,语句执行层面的优化、更佳的SQL语句使用执行计划、运行在一个稳定高效的环境,同样是高效也更符合运维的一种优化手段。下面我分享一些SQL Server在配置方面的性能优化思路,从CPU、内存、I/O、执行计划等层面,内容包含了最大并行度、资源调控器、查询提示几个功能的介绍与配置方法。
1.介绍
最大并行度是指会话可以使用的最大线程数,对于大批量查询,例如大表的扫描,使用多个线程同时扫描能成倍地提高效率;但是对于小型查询,例如只修改小表里一行的内容,则没必要使用多个线程。
一般情况下,会话最终使用多少个线程是由查询优化器决定的(可以通过option查询子句进行干预)。查询语句提交到SQL Server后会先进行解析,然后进行优化和简化(例如子查询转为对应连接、优先应用筛选条件),生成一系列执行计划,最后根据统计信息计算开销,选择合适的执行计划。最终预估的开销决定了会话使用多少并行度。
在服务器配置选项中,我们能通过“最大并行度”、“并行的开销阈值”两个配置进行调整,最大并行度的默认值是0,即不限制并行度,最大能使用到与CPU核数相等的并行度。但是对于明显有性能问题的系统,则需要考虑调整这个高级选项进行优化:
2.配置方法
3.注意事项
以下列举了一些场景作为参考:
单纯的OLTP系统由高并发的小事务组成,不适合使用太高的并行度,可以将最大并行度设置为1,即不开启并行查询;如果调整后明显感觉到执行时间太长,应用反应变慢,则可以逐步提高到2、4、8再进行观察。(对于这类语句执行频繁的小事务,执行计划的选择也是非常重要的优化方向,需要结合语句单独分析)
单纯的OLAP系统由只读长事务组成,事务执行时间都较长,例如报表统计、历史数据导出。这类事务的特点是会连接大量表、读取大量数据、进行大量计算,对于语句执行效率来说并行度越高越好。尽管官方文档推荐8核以上的服务器也使用并行度8,但在没达到CPU瓶颈的情况下可以尽可能提高OLAP系统的最大并行度,或者不限制最大并行度。
实际中更常见的是读写混合的系统,在承载应用写操作的同时也承载一些小型报表的查询,这类系统则需要进行反复的调整以达到最佳的并行度设置:写操作通常开销较小,只会用1个并行度;普通的检索开销也一般不大,使用较低并行度;报表通常开销较大,会使用较高并行度。
在CPU资源有限的情况下,配置最大并行度为1可以保证最关键的写操作能获得足够的资源;但如果读操作需要使用并行来提高效率(maxdop=1时语句执行太慢),可以适当调到2并逐步增加;如果只需要提高那些执行时间很长的查询,可以提高“并行的开销阈值”,只让高开销的查询使用并行。
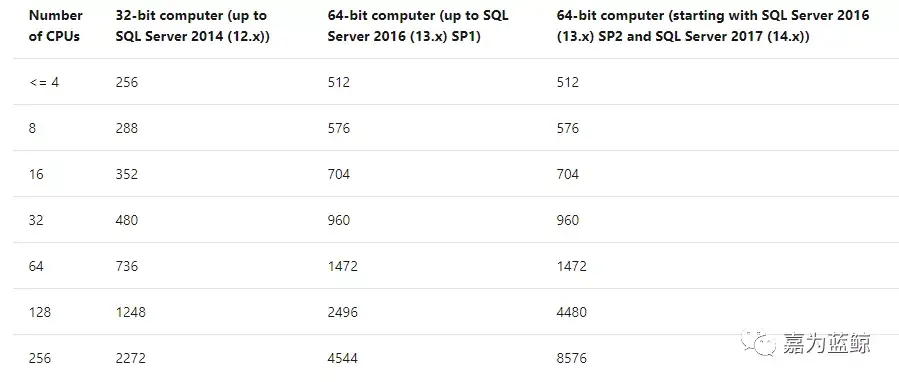
例如:一个64核的SQL2016最大线程数默认为1472,默认最大并行度为64,如果一个会话引发了阻塞,被阻塞的会话并行度都很高,那么积累了几十个会话之后线程数就满了,这在繁忙的系统上可能只会花几分钟的时间。线程数满了以后新的连接无法建立,应用开始报错,直到阻塞源消失才会恢复。
这种时候普通用户无法连接数据库,我们可以通过管理员专用通道(DAC)进行连接,在连接实例的名称前加上admin:即可,例如admin:127.0.0.1,DAC连接只能同时存在1个。线程占满的根本原因还是阻塞源的处理,提高最大线程数只是一种无奈之举。
注:日常运维不建议使用DAC连接,因为DAC连接有更高的CPU优先级,服务器压力较大时有可能会抢占普通线程,引发阻塞。
1.介绍
这是一个SQL Server 2008开始的功能,可以通过登录名(函数user_name())、当前时间(函数getdate())等会话属性进行筛选,对会话使用的CPU、物理 I/O 和内存进行人为限制,保证关键功能有充足的资源可用。
开启资源调控器后(默认关闭),会话发出请求会先通过“分类器函数”进行分类,路由到相应的“工作负荷组”,每个工作负荷组都映射到一个“资源池”,再根据资源池中设置的CPU、I/O、内存阈值来决定会话的资源分配。
可以看作是一个虚拟的SQL Server实例,默认有两个资源池(内部资源池和默认资源池),支持用户自行创建;
注:外部资源池定义的是外部进程的资源,如R 服务的rterm.exe、BxlServer.exe,与本次讨论的内部资源无关。
相当于具有分类标准的会话容器,我们可以根据工作负荷组对会话进行聚合监控。每个工作负荷组都只处于一个资源池中,默认有两个工作负荷组(内部工作负荷组和默认工作负荷组),支持用户自行创建;
对传入会话进行分类,分配到工作负荷组。
注:资源调控器不向专用管理员连接 (DAC) 施加任何控制。无需对在内部工作负荷组和资源池中运行的 DAC 查询进行分类。
2.创建与配置资源调控器
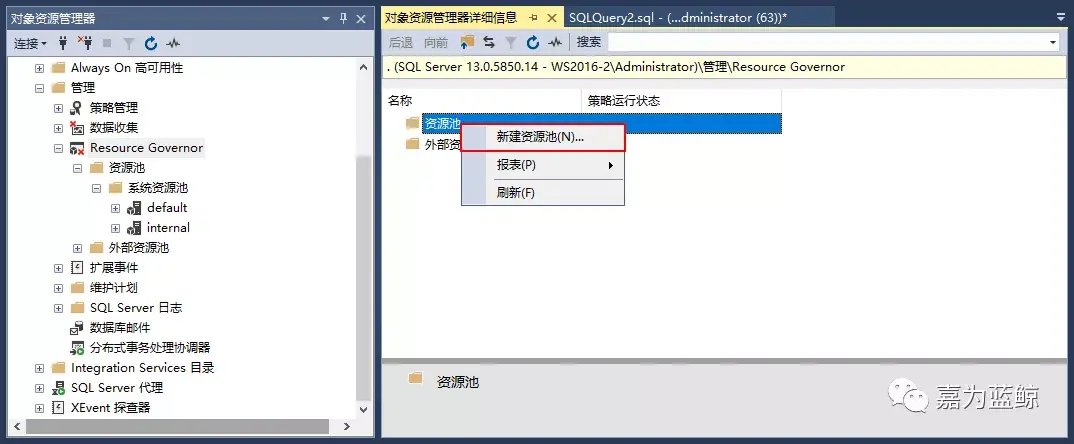
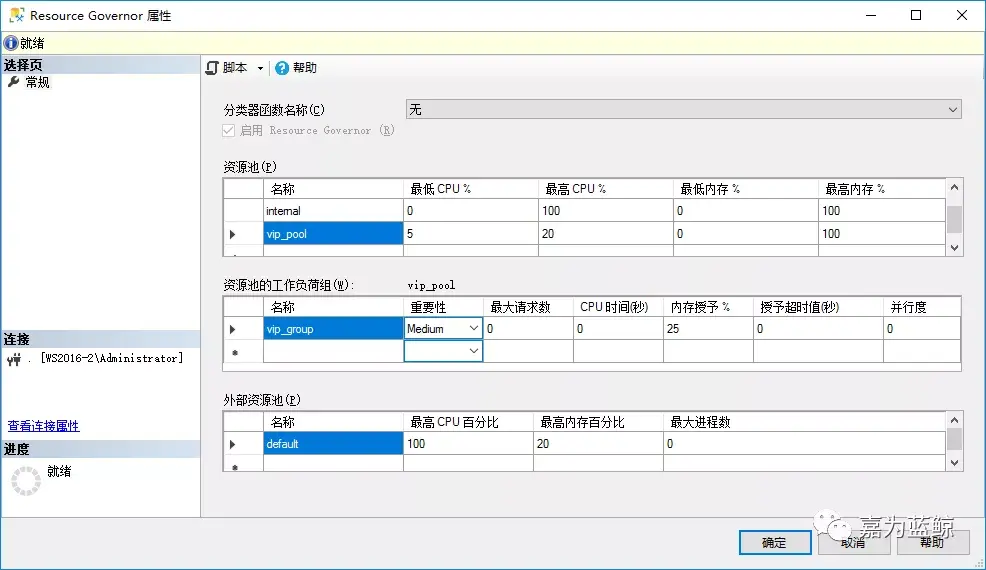
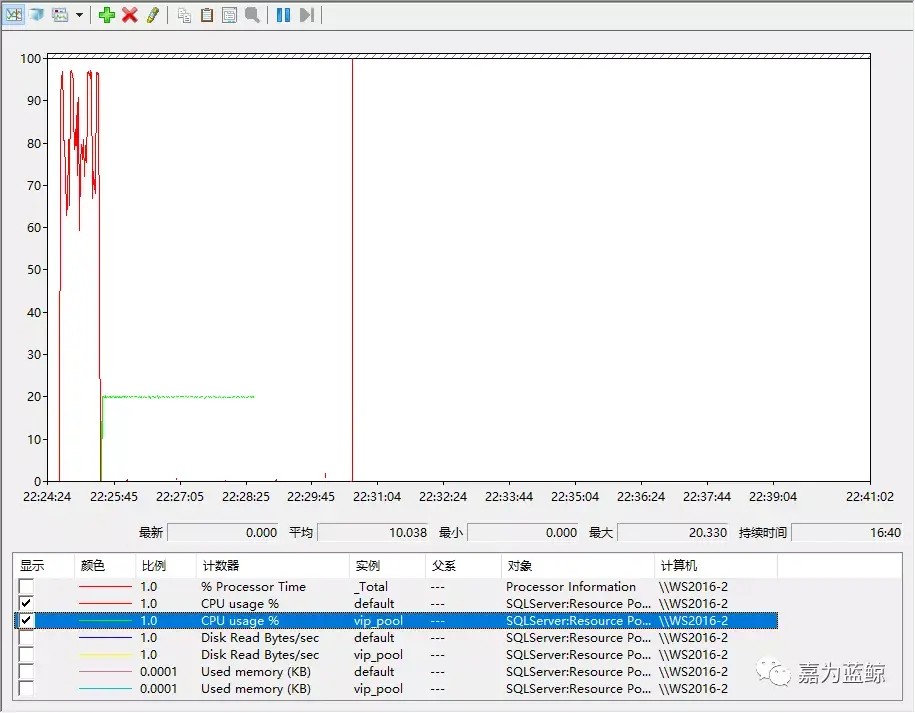
这里新建了一个资源池vip_pool、工作负荷组vip_group,最小CPU预留了5%,最大不超过20%,内存无限制,资源池中还创建了工作负荷组vip_group;(注意下方脚本指定了cap_cpu_percent=20,就是说即使系统空闲也不会使用超过20%的CPU)
USE [master]
GO
CREATE RESOURCE POOL [vip_pool] WITH(min_cpu_percent=5,
max_cpu_percent=20,
min_memory_percent=0,
max_memory_percent=100,
cap_cpu_percent=20,
AFFINITY SCHEDULER = AUTO
,
min_iops_per_volume=0,
max_iops_per_volume=0)
GO
USE [master]
GO
CREATE WORKLOAD GROUP [vip_group] WITH(group_max_requests=0,
importance=Medium,
request_max_cpu_time_sec=0,
request_max_memory_grant_percent=25,
request_memory_grant_timeout_sec=0,
max_dop=0) USING [vip_pool], EXTERNAL [default]
GO CREATE FUNCTION [dbo].[rgClassifier]()
RETURNS sysname
WITH SCHEMABINDING
AS
BEGIN
DECLARE @grp_name AS sysname;
SET @grp_name = 'default';
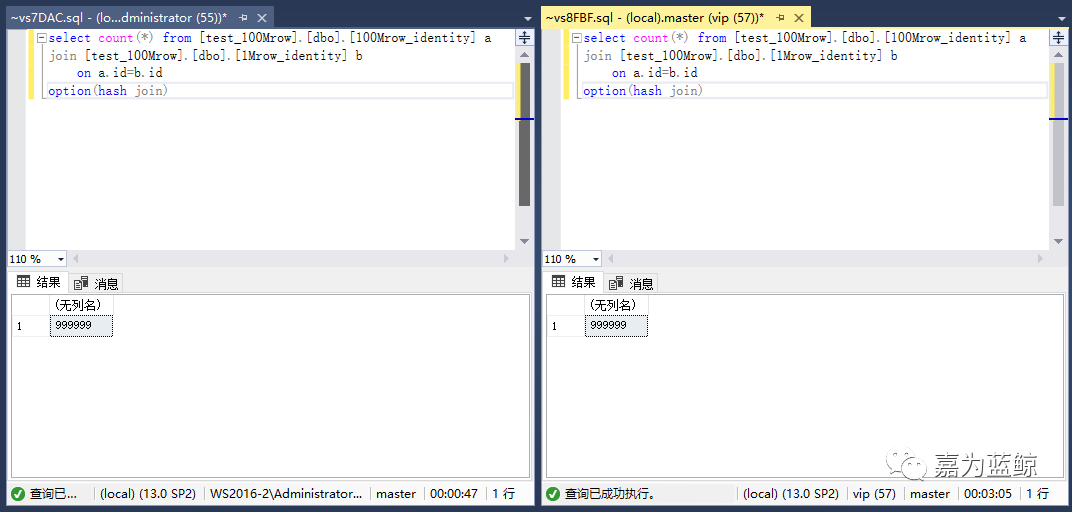
IF (USER_NAME()='vip')
begin
SET @grp_name = 'vip_group'
RETURN @grp_name
end
RETURN @grp_name;
END
GO
-- Set the classifier function for Resource Governor
ALTER RESOURCE GOVERNOR
WITH (
CLASSIFIER_FUNCTION = [dbo].[rgClassifier]
)
GO
ALTER RESOURCE GOVERNOR RECONFIGURE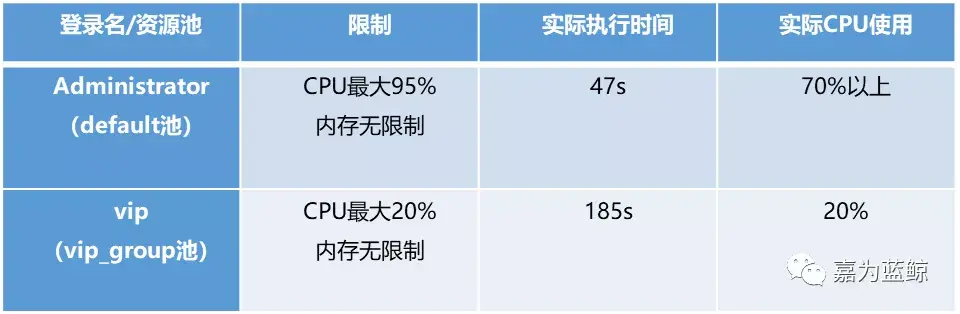
3.注意事项
查询提示可以对当前语句的执行计划进行干涉,但在通常情况下,查询优化器选择的执行计划已经足够高效,只推荐利用查询提示进行性能分析,或者用在一些特殊的语句上。
1.表提示(WITH子句)
这里只介绍一些常用项,详细使用方法参考官方文档:https://docs.microsoft.com/zh-cn/sql/t-sql/queries/hints-transact-sql-table?view=sql-server-ver15
查询不加表S锁,可能造成脏读,不强调一致性的报表类语句可以使用,防止读表时阻塞写操作,很常用。但对于AlwaysOn辅助副本,即使加了WITH(NOLOCK)也会在库级别添加SCH-S锁防止数据库被修改,这个锁会阻塞redo线程,引发主从延迟,最根本的解决方法还是优化语句,避免单个语句长时间执行。
同类的提示还有HOLDLOCK、PAGLOCK、ROWLOCK、TABLOCK、UPDLOCK、XLOCK等,适用于各种需要保证结果一致性的地方。
强制使用特定的索引,不推荐用,如果索引被删除则语句会执行失败,查询优化器没走最佳索引通常是另有原因,例如统计信息偏差太大、计算开销的误差太大。
同类的提示还有FORCESEEK、FORCESCAN,不推荐用在生产,理由同上。
WITH子句用法是加在表名后,例如:
select * from msdb.dbo.sysjobs as a with(nolock)
2.OPTION子句
这里只介绍一些常用项,详细使用方法参考官方文档:https://docs.microsoft.com/zh-cn/sql/t-sql/queries/hints-transact-sql-query?view=sql-server-ver15
指定当前语句的最大并行度。
第一节提到可以在整个实例层面配置最大并行度,对于单个查询则可以使用查询提示OPTION(MAXDOP 1)来覆盖全局设置。
仅对当前查询开启追踪标志,会覆盖全局设置。
例如OPTION(QUERYTRACEON 8649)可以将并行开销阈值降为0,即强制使用并行计划,更多追踪标志参考官方文档:https://docs.microsoft.com/zh-cn/sql/t-sql/database-console-commands/dbcc-traceon-trace-flags-transact-sql?view=sql-server-ver15
强制重新生成执行计划。
生成执行计划会带来额外的消耗,对于大型的查询语句,带来的收益可能远大于重新生成执行计划的开销;但对于执行频繁的小查询,还有其他查询提示可以干预执行计划的生成,不推荐使用。
快速返回前N行,然后查询会继续执行直至生成完整的结果。
指定当前查询的最大递归数,覆盖全局设置,防止进入无限循环。
针对特定参数生成执行计划,需要详细统计业务访问的构成,一般不建议干涉执行计划。
当缓存中存在有效的执行计划时,语句会直接沿用现有的执行计划来避免生成执行计划的性能消耗,但对于参数化的语句,例如存储过程内的语句,每次的参数可能不一样,但执行计划会使用同一个,而这个执行计划是根据第一次执行的时候传入的参数选择的,未必对于其他参数也是最优解。
例如下方语句,则参数@city_name使用值'Seattle'而非初始值,参数@postal_code使用统计数据而非初始值
CREATE PROCEDURE dbo.RetrievePersonAddress
@city_name NVARCHAR(30),
@postal_code NVARCHAR(15)
AS
SELECT * FROM Person.Address
WHERE City = @city_name AND PostalCode = @postal_code
OPTION ( OPTIMIZE FOR (@city_name = 'Seattle', @postal_code UNKNOWN) );注:存储过程sp_create_plan_guide也可以达到类似的效果,具体用法参考官方文档:https://docs.microsoft.com/zh-cn/sql/relational-databases/system-stored-procedures/sp-create-plan-guide-transact-sql?view=sql-server-ver15
强制语句使用MERGE JOIN,仅适用性能优化排查,或者明确使用场景的语句。
同类型的还有:
{ HASH | ORDER }GROUP
{ CONCAT | HASH | MERGE }UNION
{ LOOP | MERGE | HASH }JOIN
FORCE ORDER
OPTION子句用法是加在整个查询语句后,例如:
select * from msdb.dbo.sysjobs as a with(nolock) join msdb.dbo.sysjobhistory as b with(nolock) on a.job_id = b.job_id where a.[name] = 'syspolicy_purge_history'
option(maxdop 1)




